
RAG in AI: What Does It Even Mean

What is Retrieval-Augmented Generation (RAG)?
Retrieval-augmented generation (RAG) refers to a type of language model that generates responses to queries or prompts by retrieving relevant information from a knowledge base, and then uses it as context when generating output.
This technique enhances the functioning of large language models (LLMs) by making their responses more accurate and up-to-date. As the name suggests, RAG combines both retrieval-based and generative-based techniques.
Most large language models in the market generate responses based on the data they are trained on. They can expand upon this knowledge to an extent and tailor responses based on the user prompts. However, with RAG implementation, they become capable of using external data sources to fetch relevant information. This reduces some of the common challenges that LLMs face such as hallucination, lack of source citations, and many more.
This blog post focuses on RAGs within the context of LLMs. It should be noted that the core concept can be applied to other forms of Generative AI models, including image, audio, video, and other mediums.
Why the Need for Retrieval-Augmented Generation?
The development of RAG was primarily to overcome challenges posed by large language models, such as inaccurate responses, lack of source citations, hallucinations when forming responses, and the high cost of training LLMs, which requires massive computational and data resources.
A large language model generates a text-based response to a user's prompt. It uses predefined datasets on which it was trained to form this response. However, it is cumbersome and expensive to retrain the model with updated data on a timely basis. This leads to LLMs producing outdated responses to prompts or hallucinating and making up responses when they do not have sufficient information.
How does Retrieval-Augmented Generation Work?
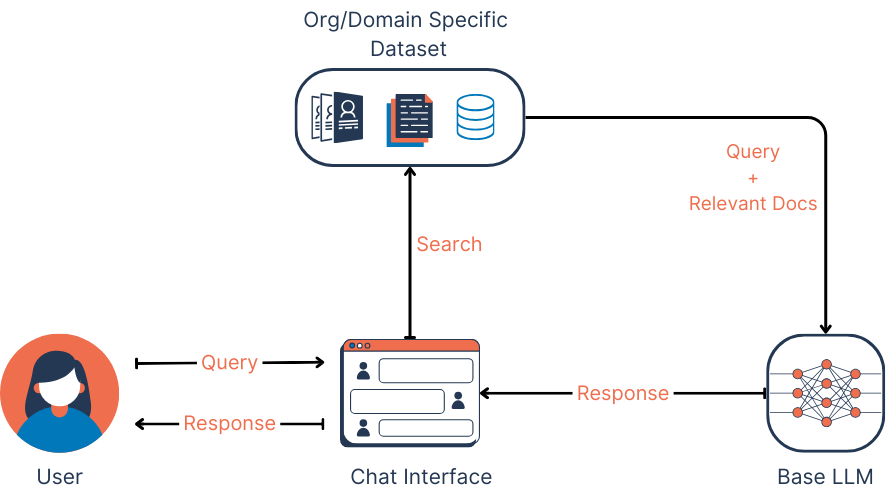
When an LLM deployed within a RAG model receives a prompt, instead of generating a response from what it already knows, it queries an external content source. A retrieval-based model is then deployed to extract relevant data from an online content source. This content source can be open, like the internet, or closed, like medical records of a hospital. When relevant data is extracted by the retrieval model, the generative model then generates an original, human-like response for the user.
In a RAG model, the retrieval model locates and fetches relevant data based on a user query, while the generative model formulates that data into context-appropriate responses. The responses from a RAG model also provide information about the sources of the data, building credibility and trust among users. Thus, this builds credibility and trust among users.
TLDR; How does a Retrieval-Augmented Generation Work?
- Process user input
- Analyse & interpret the prompt
- Feed it to a retrieval model
- Extract data from the retrieval model
- Pass the information to a generative model
- Craft a coherent response for the user
What are the Benefits of Using RAG?
RAG combines the strengths of retrieval and generative models while overcoming their individual challenges.
Here are some benefits of using RAG over just deploying LLMs:
- Higher accuracy
RAG-powered LLMs hallucinate less because their responses are based on factual data. Since the retrieval model provides context to the generative model, it generates more accurate and reliable responses.
- Well-collated information from multiple sources
Multiple sources of information can be fed to a generative model to generate a rich, context-appropriate response to the user query.
- Easier to train
Training the large language model is an enormous task, and constantly updating it with the latest information is quite difficult and prohibitively expensive. So, when a retrieval model is deployed with a generative model, it is easier to keep updating the pre-existing data source of the retrieval model with the latest information.
- Source citations
RAG does not inherently provide source citations, but it can be specifically designed into the model's response generation to include them. This makes the responses more reliable and easier to verify, helping to build user trust and create transparency with AI-generated content
- Higher efficiency & scalability
Retrieval models offer the advantage of independent scalability; as the volume of data expands or the frequency of queries rises, the retrieval system can be scaled up to manage the larger workload. This capability enhances both the performance and the scalability of the entire system, ensuring it remains responsive and efficient even as demands grow.
Conclusion
Retrieval-augmented generation overcomes major LLM challenges and generates more accurate, reliable, and context-aware responses to prompts. This makes it ideal for enterprises looking to implement reliable and efficient models. The dual-model setup reduces hallucinations significantly since it is grounded in factual data. Implementing this approach can be highly beneficial for an organization to form a highly-efficient and build a robust framework.