
Unlocking the Power of Data Lakehouses: Why They Matter Now and How to Get Started

The data lakehouse represents the next step in the ongoing evolution of data management, driven by the need for more efficient and capable data processing. In this article, we explore the journey that led to the development of the data lakehouse, examining how each stage in the evolution of data management paved the way for this innovative solution. The data lakehouse seeks to combine the strengths of earlier approaches while overcoming their limitations.
The Origins: Understanding OLTP Databases and Their Limitations
Data warehouses and Online Analytical Processing (OLAP) systems emerged to tackle the limitations of OLTP databases in managing analytical workloads. Tailored specifically for querying and analysis, these systems enhanced the performance of analytical queries and provided structured environments for data to be cleaned, transformed, and stored for business intelligence purposes. However, these on-premises solutions came with significant drawbacks: they were expensive to maintain, challenging to operate, and difficult to scale. The tight integration of storage and compute resources often resulted in inefficiencies, forcing organizations to pay for more capacity than necessary.
Data Lakes: A Revolutionary Shift in Data Management
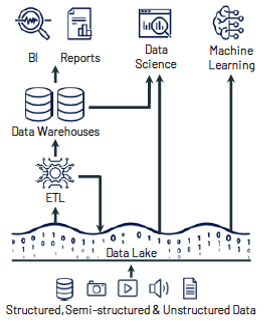
Hadoop and similar technologies paved the way for a more affordable approach to storing both structured and unstructured data, giving rise to the concept of data lakes. The key benefit of data lakes was their ability to store massive amounts of raw data in its native formats, enabling organizations to process and transfer only the data needed for analysis to data warehouses. However, leveraging data lakes directly for analytics proved challenging; they lacked the processing power and optimized structures of data warehouses, making them less effective as standalone analytical tools.
Embracing the Cloud: Separating Storage and Compute for Enhanced Efficiency
The quest for a better solution arose as data warehouses became more expensive and data lakes failed to deliver the necessary analytical capabilities. Organizations needed a system that could merge the vast storage capacity of data lakes with the analytical strength of data warehouses, all while being cost-effective, scalable, and efficient. This pursuit ultimately paved the way for the data lakehouse — an innovative architecture designed to overcome the limitations of earlier approaches.
The Search for a New Solution
As data warehouses became increasingly expensive and data lakes fell short in analytical capabilities, organizations sought an alternative that could blend the best of both worlds. The need was clear: a system that combined the extensive storage capacity of data lakes with the robust analytical power of data warehouses, while also being cost-effective, scalable, and efficient. This pursuit led to the development of the data lakehouse — a groundbreaking architecture designed to overcome the limitations of its predecessors.
The Emergence of the Data Lakehouse
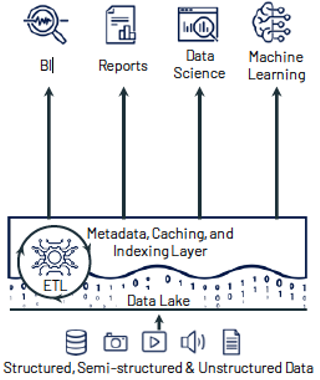
The data lakehouse addresses the shortcomings of traditional data warehouses and data lakes by merging their strengths into a unified solution. This innovative architecture offers the expansive storage capabilities of data lakes alongside the powerful analytical processing of data warehouses, creating a versatile and efficient platform.
Key Technologies Powering the Data Lakehouse
• Cloud-based Object Storage: Services like Amazon S3, Azure Data Lake Storage (ADLS), and MinIO provide scalable, secure, and cost-effective storage solutions. These cloud-based object storage platforms form the backbone of a data lakehouse, allowing for the storage of vast amounts of both structured and unstructured data.
• Columnar Storage with Apache Parquet: The introduction of Apache Parquet, a binary columnar storage format, transformed data storage practices. Parquet enables efficient data compression and encoding, reducing storage costs while boosting query performance due to its columnar architecture.
• Table Formats like Apache Iceberg: Open-source table formats such as Apache Iceberg are critical to the functionality of data lakehouses. They allow large datasets to be managed as traditional tables, complete with ACID (atomicity, consistency, isolation, durability) transactions and time-travel capabilities, bringing the reliability of databases to the scalability of data lakes.
• Data Management Catalogs: Tools like Apache Polaris and Tabular enhance data governance and collaboration by enabling seamless transportation of tables across different tools and environments.
The Data Lakehouse Platform
Platforms that integrate these technologies deliver a seamless user experience, offering:
• Unified Data Access: Data federation across various sources, enabling users to access and query data regardless of its location.
• Enhanced Data Governance: Comprehensive tools for monitoring, securing, and governing data within the lakehouse.
• Advanced Query Engines: High-performance query engines designed for efficient querying of large datasets.
• Semantic Layer: A unified data view that abstracts underlying complexities and presents a consistent data model for end users.
This combination of features and technologies positions the data lakehouse as the ideal solution for modern data management needs.
The quest for a better solution arose as data warehouses became more expensive and data lakes failed to deliver the necessary analytical capabilities. Organizations needed a system that could merge the vast storage capacity of data lakes with the analytical strength of data warehouses, all while being cost-effective, scalable, and efficient. This pursuit ultimately paved the way for the data lakehouse — an innovative architecture designed to overcome the limitations of earlier approaches.
To deploy your own data lakehouse in hours on your own cloud, Or just want to know more about how it works?
Get in touch with me here.